Example of indexing and searching in Lucene.Net using C#
This is a simple example of how to add a document to a Lucene.Net index and then search for a word, using C#. This example also shows how to search a numeric field for a number. Here, I also show how to debug your own analyzer by printing the tokens it generates to the screen.
I've used Lucene.Net version 4.8.0 (beta00005). My project was a simple console application, targeting .NET Framework 4.7. The three packages I installed were:
lucene.net.4.8.0-beta00005 (add reference to Lucene.Net.dll)
lucene.net.analysis.common.4.8.0-beta00005 (add reference to Lucene.Net.Analysis.Common.dll)
lucene.net.queryparser.4.8.0-beta00005 (add reference to Lucene.Net.QueryParser.dll)
For the sake of ease of explanation, I didn't factor out constants or member variables. This makes it so that I can talk about each method individually.
AddDocument
The AddDocument method takes in a Document and adds it to the index by first putting it through our custom analyzer StemmedEnglishAnalyzer. More on StemmedEnglishAnalyzer later on.
Search
This method accesses the index, searching in both title and body for a specified text, while exactly matching the collectionId. I've included the collectionId query to show how a consumer might prune search hits.
Note how I've used BooleanQuery to aggregate two queries:
1. A MultiFieldQuery on fields "title" and "body"
2. A NumericRangeQuery on field "collectionId"
The search query itself is put through my custom StemmedEnglishAnalyzer.
The last part of the method is a straightforward enumerate-and-print for each returned document.
PrintTokens
Full-text search engines such as Lucene.Net usually transform words (tokens) inside a document, before storing them. One benefit of this is that the consumer can search for words that share the same morphological stem. For example, the words "argued" and "arguing" share the stem "argu"; an indexed document containing "argued" would be returned as a search hit when searching for "arguing".
The PrintTokens method simply prints to the screen the tokens generated from the input text. This is a great way to debug your analyzer.
Putting it all together: Main
The Main method is simple:
1. It prints the tokens of a hard-coded body text
2. It creates a document
3. It indexes the document via AddDocument
4. It searches for "expenses" in collection 123, yielding results
4. It searches for "expenses" in collection 456, yielding no results (collection doesn't exit)
The StemmedEnglishAnalyzer analyzer
Our custom analyzer is in charge of a few things:
1. It converts all words to lowercase
2. It removes all known English stopwords (overly frequent words that usually don't improve search efficiency; examples: "the", "it")
3. It converts all words to their stems (examples: "localization"->"local", "expensive"->"expens")
The resulting words (tokens) can either be written to the index (see AddDocument method) or searched (see Search method).
For debugging the analyzer, see the PrintTokens method.
The PorterStemFilter I used is an implementation of the Porter Stemming Algorithm (first published in 1980).
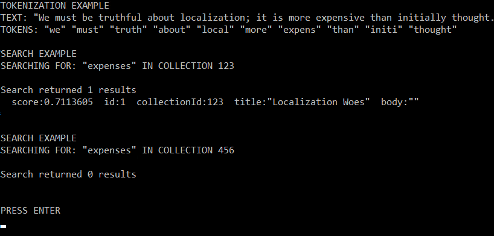 A sample run of the Main method shown above
A sample run of the Main method shown above
I've used Lucene.Net version 4.8.0 (beta00005). My project was a simple console application, targeting .NET Framework 4.7. The three packages I installed were:
lucene.net.4.8.0-beta00005 (add reference to Lucene.Net.dll)
lucene.net.analysis.common.4.8.0-beta00005 (add reference to Lucene.Net.Analysis.Common.dll)
lucene.net.queryparser.4.8.0-beta00005 (add reference to Lucene.Net.QueryParser.dll)
For the sake of ease of explanation, I didn't factor out constants or member variables. This makes it so that I can talk about each method individually.
// Adds a document to the index
private static void AddDocument( Document doc ) {
using( FSDirectory directory = FSDirectory.Open( "LuceneIndex" ) )
using( Analyzer analyzer = new StemmedEnglishAnalyzer() ) {
IndexWriterConfig config =
new IndexWriterConfig( LuceneVersion.LUCENE_48, analyzer );
using( IndexWriter writer =
new IndexWriter( directory, config ) ) {
writer.AddDocument( doc );
writer.Commit();
}
}
}
AddDocument
The AddDocument method takes in a Document and adds it to the index by first putting it through our custom analyzer StemmedEnglishAnalyzer. More on StemmedEnglishAnalyzer later on.
// Searches for all matching documents
private static void Search( long collectionId, string text ) {
Console.WriteLine();
Console.WriteLine( "SEARCH EXAMPLE" );
Console.WriteLine(
"SEARCHING FOR: \"" + text + "\" IN COLLECTION " + collectionId );
using( FSDirectory directory = FSDirectory.Open( "LuceneIndex" ) )
using( Analyzer analyzer = new StemmedEnglishAnalyzer() )
using( IndexReader reader = DirectoryReader.Open( directory ) ) {
IndexSearcher searcher = new IndexSearcher( reader );
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(
LuceneVersion.LUCENE_48,
new[] { "title", "body" },
analyzer
);
Query searchTermQuery = queryParser.Parse( text );
Query collectionIdQuery = NumericRangeQuery.NewInt64Range(
"collectionId", collectionId, collectionId, true, true );
BooleanQuery aggregateQuery = new BooleanQuery() {
{ searchTermQuery, Occur.MUST },
{ collectionIdQuery, Occur.MUST }
};
// perform search
TopDocs topDocs = searcher.Search( aggregateQuery, 10 );
Console.WriteLine(
"\nSearch returned {0} results",
topDocs.ScoreDocs.Length
);
// display results
foreach( ScoreDoc scoreDoc in topDocs.ScoreDocs ) {
float score = scoreDoc.Score;
int docId = scoreDoc.Doc;
Document doc = searcher.Doc( docId );
// fields of search hit
string id = doc.Get( "id" );
string cId = doc.Get( "collectionId" );
string title = doc.Get( "title" );
string body = doc.Get( "body" );
Console.WriteLine(
" score:{0} id:{1} collectionId:{2} " +
"title:\"{3}\" body:\"{4}\"",
score,
id,
cId,
title,
body
);
}
}
Console.WriteLine();
}
Search
This method accesses the index, searching in both title and body for a specified text, while exactly matching the collectionId. I've included the collectionId query to show how a consumer might prune search hits.
Note how I've used BooleanQuery to aggregate two queries:
1. A MultiFieldQuery on fields "title" and "body"
2. A NumericRangeQuery on field "collectionId"
The search query itself is put through my custom StemmedEnglishAnalyzer.
The last part of the method is a straightforward enumerate-and-print for each returned document.
// Lists the tokens generated from the specified text.
// This is a good way to debug your analyzer setup.
private static void PrintTokens( string text ) {
Console.WriteLine( "TOKENIZATION EXAMPLE" );
Console.WriteLine( "TEXT: \"" + text + "\"" );
Console.Write( "TOKENS: " );
using( FSDirectory directory = FSDirectory.Open( "LuceneIndex" ) )
using( Analyzer analyzer = new StemmedEnglishAnalyzer() )
using( TokenStream tokenStream =
analyzer.GetTokenStream( "body", text ) ) {
tokenStream.Reset();
while( tokenStream.IncrementToken() ) {
ICharTermAttribute attribute = tokenStream
.GetAttribute();
Console.Write( "\"" + attribute.ToString() + "\" " );
}
tokenStream.End();
}
Console.WriteLine();
}
PrintTokens
Full-text search engines such as Lucene.Net usually transform words (tokens) inside a document, before storing them. One benefit of this is that the consumer can search for words that share the same morphological stem. For example, the words "argued" and "arguing" share the stem "argu"; an indexed document containing "argued" would be returned as a search hit when searching for "arguing".
The PrintTokens method simply prints to the screen the tokens generated from the input text. This is a great way to debug your analyzer.
static void Main( string[] args ) {
try {
System.IO.Directory.Delete( "LuceneIndex", recursive: true );
} catch { }
string body = "We must be truthful about localization; "+
"it is more expensive than initially thought.";
PrintTokens( body );
Document doc = new Document();
doc.Add( new Int64Field( "id", 1, Field.Store.YES ) );
doc.Add( new TextField( "title", "Localization Woes", Field.Store.YES ) );
doc.Add( new TextField( "body", body, Field.Store.NO ) );
doc.Add( new Int64Field( "collectionId", 123, Field.Store.YES ) );
AddDocument( doc );
Search( 123, "expenses" );
Search( 456, "expenses" );
Console.WriteLine( "\nPRESS ENTER" );
Console.ReadLine();
}
Putting it all together: Main
The Main method is simple:
1. It prints the tokens of a hard-coded body text
2. It creates a document
3. It indexes the document via AddDocument
4. It searches for "expenses" in collection 123, yielding results
4. It searches for "expenses" in collection 456, yielding no results (collection doesn't exit)
public class StemmedEnglishAnalyzer : Analyzer {
protected override TokenStreamComponents CreateComponents(
string fieldName,
TextReader reader
) {
Tokenizer lowerCaseTokenizer =
new LowerCaseTokenizer( LuceneVersion.LUCENE_48, reader );
PorterStemFilter porterStemFilter =
new PorterStemFilter( lowerCaseTokenizer );
StopFilter stopFilter = new StopFilter(
LuceneVersion.LUCENE_48,
porterStemFilter,
EnglishAnalyzer.DefaultStopSet
);
return new TokenStreamComponents( lowerCaseTokenizer, stopFilter );
}
}
The StemmedEnglishAnalyzer analyzer
Our custom analyzer is in charge of a few things:
1. It converts all words to lowercase
2. It removes all known English stopwords (overly frequent words that usually don't improve search efficiency; examples: "the", "it")
3. It converts all words to their stems (examples: "localization"->"local", "expensive"->"expens")
The resulting words (tokens) can either be written to the index (see AddDocument method) or searched (see Search method).
For debugging the analyzer, see the PrintTokens method.
The PorterStemFilter I used is an implementation of the Porter Stemming Algorithm (first published in 1980).
A sample run of the Main method shown above